Contrastive self-supervised learning for spatio-temporal analysis of lung ultrasound videos
Li Chen*, Jonathan Rubin*†, Jiahong Ouyang, Naveen Balaraju, Shubham Patil, Courosh Mehanian, Sourabh Kulhare, Rachel Millin, Kenton W. Gregory, Cynthia R. Gregory, Meihua Zhu, David O. Kessler, Laurie Malia, Almaz Dessie, Joni Rabiner, Di Coneybeare, Bo Shopsin, Andrew Hersh, Cristian Madar, Jeffrey Shupp, Laura S. Johnson, Jacob Avila, Kristin Dwyer, Peter Weimersheimer, Balasundar Raju, Jochen Kruecker, Alvin Chen.
* equal contribution
†work done while employed at Philips
IEEE International Symposium on Biomedical Imaging (ISBI) , 2023, Cartagena, Colombia (April 18 - 21).
Abstract:
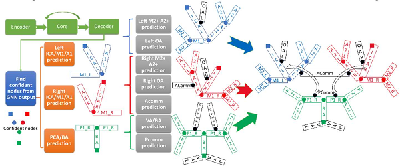
Self-supervised learning (SSL) methods have shown promise for medical imaging applications by learning meaningful visual representations, even when the amount of labeled data is limited. Here, we extend state-of-the-art contrastive learning SSL methods to 2D+time medical ultrasound video data by introducing a modified encoder and augmentation method capable of learning meaningful spatio-temporal representations, without requiring constraints on the input data. We evaluate our method on the challenging clinical task of identifying lung consolidations (an important pathological feature) in ultrasound videos. Using a multi-center dataset of over 27k lung ultrasound videos acquired from over 500 patients, we show that our method can significantly improve performance on downstream localization and classification of lung consolidation. Comparisons against baseline models trained without SSL show that the proposed methods are particularly advantageous when the size of labeled training data is limited (e.g., as little as 5% of the training set).
Index Terms—Self-supervised learning, contrastive learning, spatio-temporal augmentation, lung ultrasound
This is a joint work from multiple clinical sites. The annotations require huge amount of human efforts. So this paper has the most authors I ever published.

test123111
admin1
memeda
 Login
Login